| Author: | Martin Blais <blais@furius.ca> |
|---|---|
| Date: | 2004-03-23 |
Abstract
Details and notes on the complete redesign of curator.
curator generates static web pages. You should be able to zip and plop the resulting directory on any web server space and it should work. No need to run CGI scripts, install PHP or do any kind of webserver configuration. curator output should work on any of the free servers. This is also a great solution for archiving: burning the result on a CD or DVD will allow you to view your pictures direct from the media, just point your browser at it.
curator generates hrefs as relative links. This allows you to simply move the photos directory, and also to browse it on a webserver, or directly on your local filesystem. It is also possible to instruct curator to use a fixed URL as a prefix as well;
curator has very minimal dependencies to run: PIL, or ImageMagick, which allows it to work on a variety of platforms. Once the files are generated, all you need is a web browser.
multiple views: curator can generate multiple views of your photos, you can make different slide-shows with the same directories, by specifying simple lists of photos for each view. Separate HTML is generated for each view. All images and thumbnails are shared.
smart image maps: the images can contain areas to move to the next and previous photo in a view. You click on the right or left portion of the image itself to move in the list.
smart preprocessing: curator comes with facilities to reduce and rotate your large images to a size suited for on-screen viewing.
annotation: xml files..
clean output: there are various possibilities for generating the output files of curator separately from the original images;
modular architecture:
In fact, the curator program is now only a front-end that patches up the modules together in the most usual order. You could easily make your own mix of modules to customize the process.
support EXIF tags:
support video?
discovery:
[dataflow] input: root directory output: list of images (already paired up)
Role: find input images, set location strategy for corresponding thumbnails and reduced images, if necessary.
Important
We store all paths as paths relative to the root directory. We prepend the root directory whenever we need to have real file access.
image data:
[dataflow] input: list of images output: list of images w/ metadata
Role: set location of description file and open and parse it.
E.g.: find and read XML file, open image file and read EXIF tags.
process:
[dataflow] input: images, images data creates: reduced images w/ copyright and all, thumbnails output: reduced image, rotate, add copyright, etc.
Role: process images for reduction.
thumbproc:
[dataflow] input: image, image data output: thumbnail image.
Role: produce a thumbnail from an image.
global data:
[dataflow] input: root directory output: global metadata (lists of images in tracks)
generation:
[dataflow] input: list of complete images w/ metadata and thumbnail info input: global metadata (lists of images in tracks) output: html pages
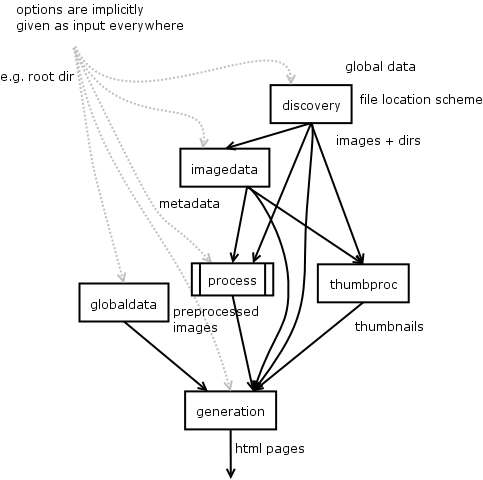
Dataflow diagram for the curator redesign.
Fundamental Problem: discovery generates the description file location and the description file influences the browseable image.
Problem: when do the thumbnails get generated?
2 use cases:
--no-thumbnails mode: do no generate thumbnails bt link by text
- need to support this throughout